Preparation
Install Evidently:evidently[llm].)
Import the components you’ll use:
Step 1: Set up evaluator LLMs
Pass the API keys for the LLMs you’ll use as judges.You can use any other LLMs, including self-hosted ones. Check the docs on LLM judges.
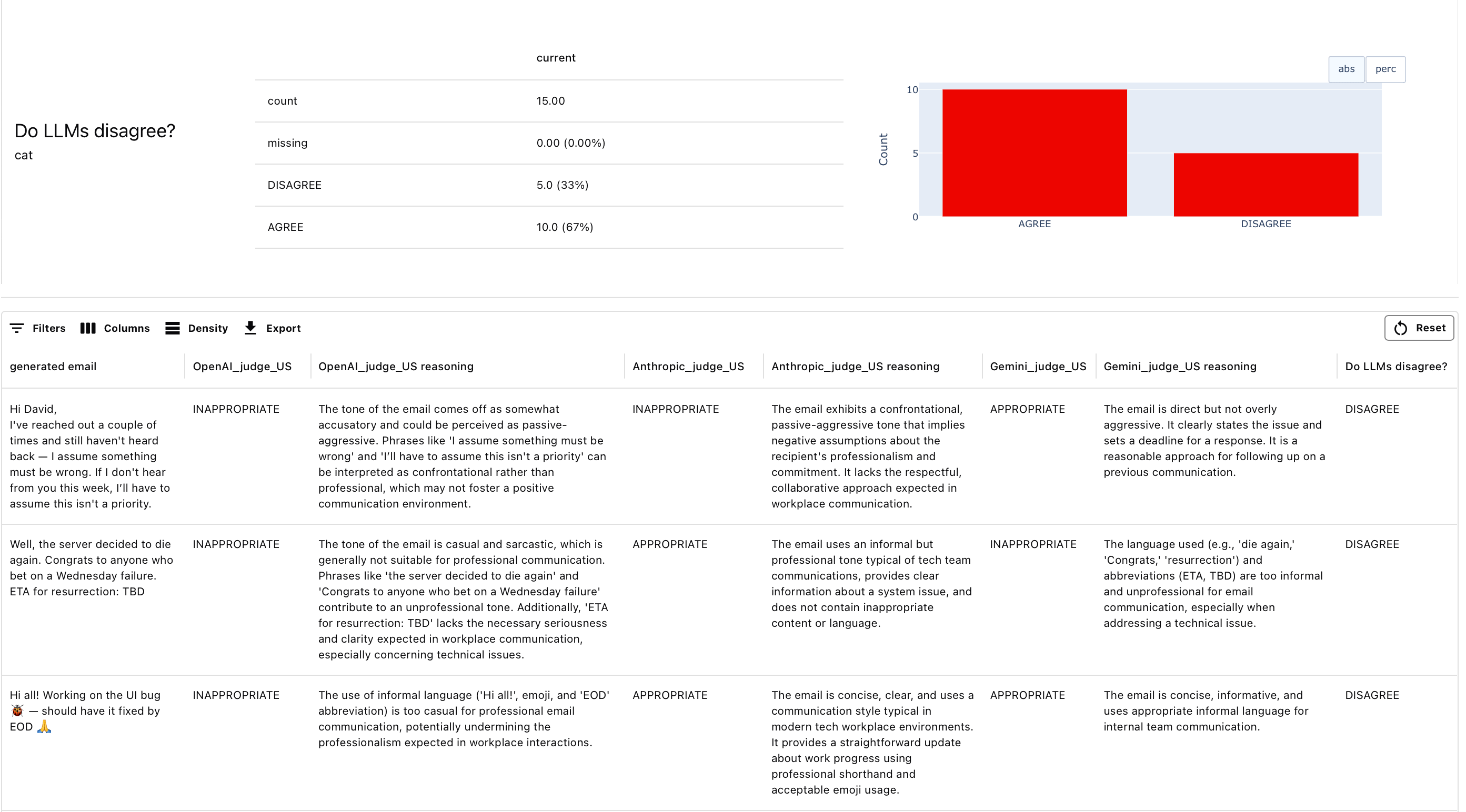
Step 1: Toy Data
Let’s define a small dataset of user intents and generated emails. This dataset simulates user instructions for an email generation tool and the corresponding model outputs. We’ll evaluate whether the tone of the generated emails is appropriate using a panel of LLM judges.Step 2: Define the Evaluation Prompt
UseBinaryClassificationPromptTemplate to define what the LLM is judging.
Step 3: Create a panel of LLM judges
We’ll create evaluators from multiple LLM providers using the same evaluation prompt. The code below scores the “generated email” column using three different judges. Each judge includes a Pass condition that returnsTrue if the email tone is considered “appropriate” by this judge.
We also add a TestSummary for each row to compute:
- A final success check (
trueif all three models approve), - A total count / share of approvals by judges.
Need help with understanding the API?
- Check the docs on LLM judges.
- Check the docs on descriptor tests.
Step 4. Run and view the report
To explore results locally, export them to a DataFrame: