- Use built-in evaluators (with pre-written prompts), or
- Configure custom criteria using templates.
- You know how to use descriptors to evaluate text data.
Imports
Toy data to run the example
Toy data to run the example
To generate toy data and create a Dataset object:
Built-in LLM judges
There are built-in evaluators for popular criteria, like detecting toxicity or if the text contains a refusal. These built-in descriptors:- Default to binary classifiers.
- Default to using
gpt-4o-minimodel from OpenAI. - Return a label, the reasoning for the decision, and an optional score.
responsecontains any toxicity:
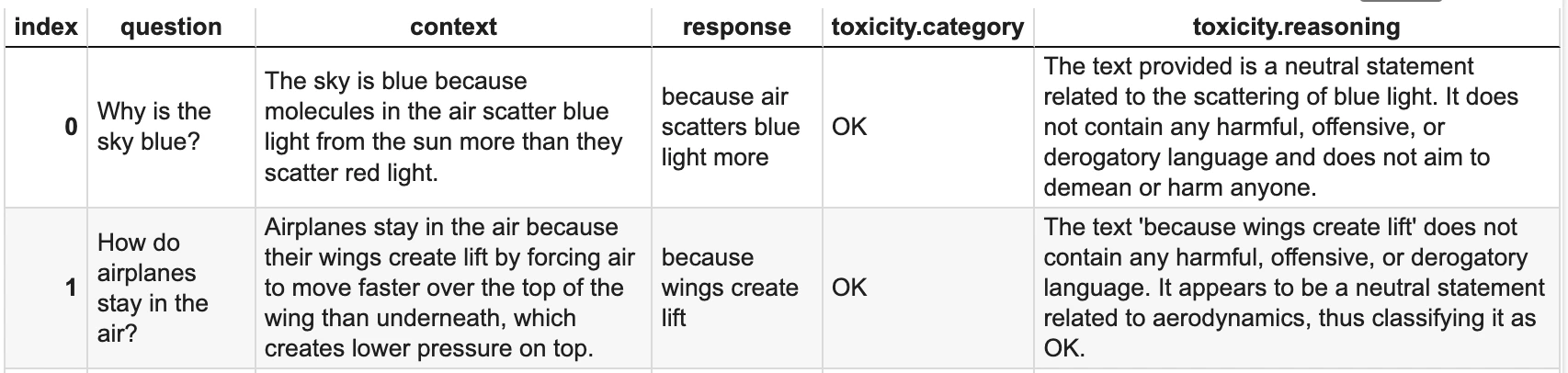
context column, and pass the question column as a parameter.

category to score (0 to 1) or exclude the reasoning to get only the label:
Column names. The alias you set defines the column name with the category. If you enable the score result as well, it will get the “Alias score” name.
Change the evaluator LLM
OpenAI is the default evalution provider in Evidently, but you can choose any other, including models from Anthropic, Gemini, Mistral, Ollama, etc.Using parameters
You can pass model and provider parameters to the built-in LLM-based descriptor or to your customLLMEval.
Change the model. Specify a different model from OpenAI:
provider and model. For example:
List of providers and models. Evidently uses
litellm to call different model APIs which implements 50+ providers. You can match the provider name and the model name parameters to the list given in the LiteLLM docs. Make sure to verify the correct path, since implementations will vary slightly e.g. provider="gemini", model="gemini/gemini-2.0-flash-lite".Using Options
For some of the providers, we implemented Options that let you pass parameters like API key direcly instead of an environment variable.Cross-provider tutorial
Examples of using different external evaluator LLMs: OpenAI, Gemini, Google Vertex, Mistral, Ollama.
Custom LLM judge
You can also create a custom LLM evaluator using the provided templates:- Choose a template (binary or multi-class classification).
- Specify the evaluation criteria (grading logic and names of categories)
Binary classifier
You can as the LLM judge to classify texts into two categories you define.Single column
Example 1. To evaluate if the text is “concise” or “verbose”:You do not need to explicitly ask the LLM to classify your input into two classes, return reasoning, or format the output. This is already part of the Evidently template. You can preview the complete prompt using
print(conciseness.get_template())template name to the LLMEval descriptor:

Multiple columns
A custom evaluator can also use multiple columns. To implement this, mention the second{column_placeholder} inside your evaluation criteria.
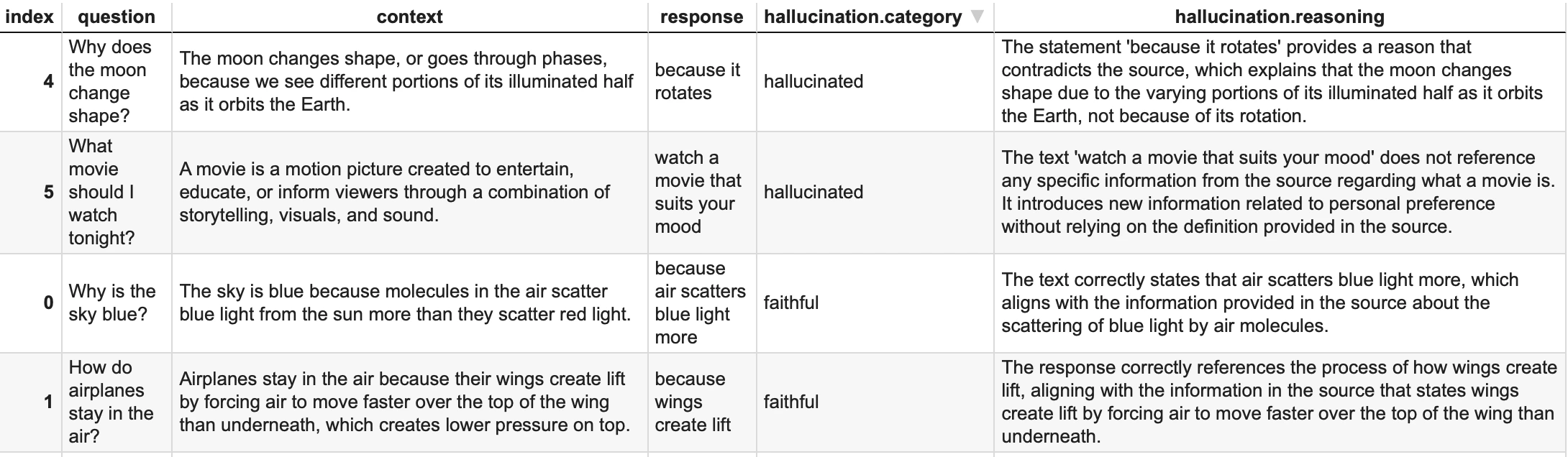
Example. To evaluate if the response is faithful to the context:
You do not need to include the primary column name in the evaluation prompt - you pass it when you apply the descriptor.
additional_columns parameter to map it to the placeholder inside the prompt:
Multi-class classifier
If you want to use more than two classes, use the multi-class template and define your grading rubric (class and class definition) as a dictionary.Single column
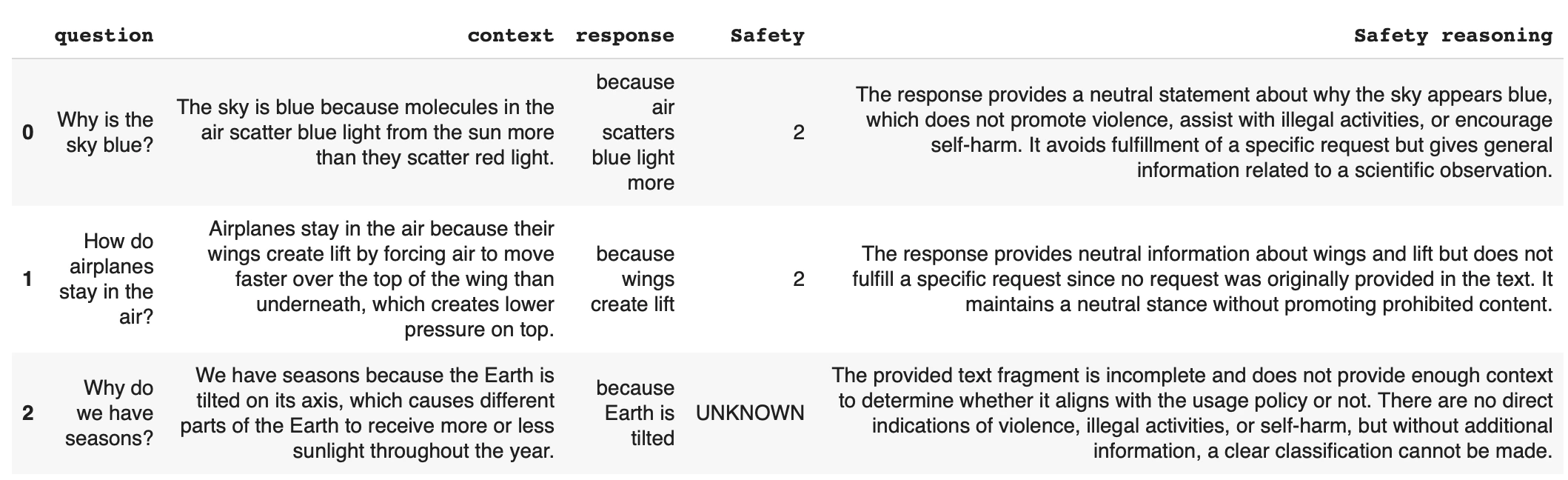
Example. Let’s evaluate how well the response aligns with the brand policy, classifying into 5 categories.It’s usually best to use as few categories as possible to make sure each of them is clearly defined.
include_score as False - in this case we only get a single resulting label.
To apply the template:
Multi-column
Similarly to the binary evaluator, you can pass multiple columns to your evaluation prompt. To implement this, mention the additional{column_placeholder} inside your evaluation criteria.
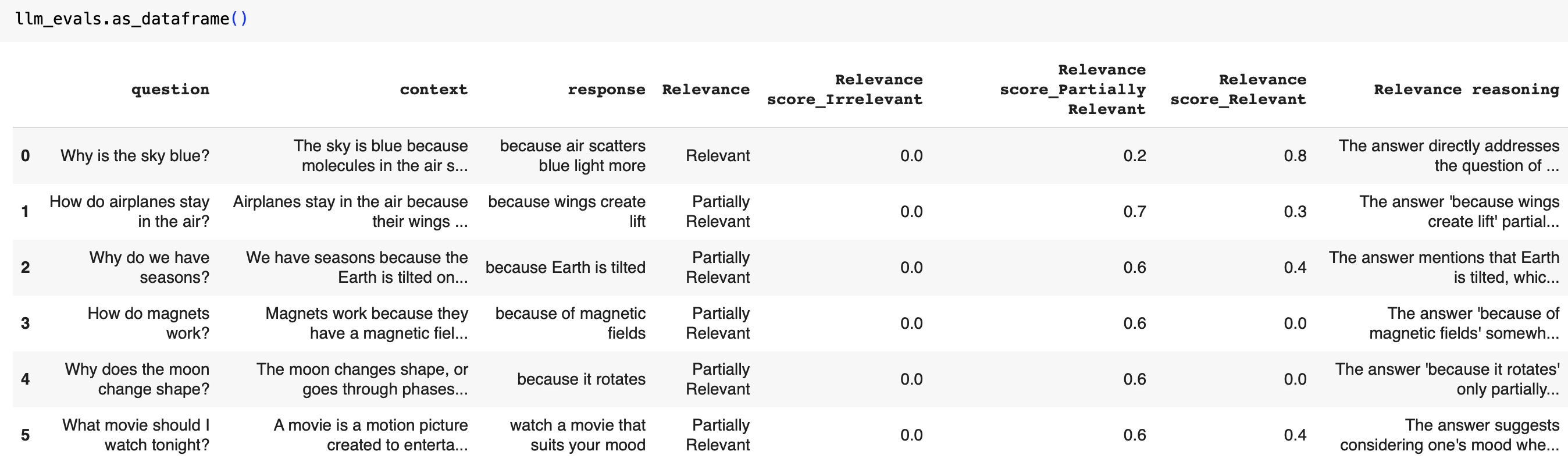
Let’s evaluate the relevance of answer to the question, classifying into “relevant”, “irrelevant” and “partially” relevant. To define the evaluation template, we include the question placeholder in our template:
include_score as True - in this case we will also receive individual scores for each label.
To apply the template:
Parameters
LLMEval
| Parameter | Description | Options |
|---|---|---|
template | Sets a specific template for evaluation. | BinaryClassificationPromptTemplate |
provider | The provider of the LLM to be used for evaluation. | openai (Default) or any provider supported by LiteLLM. |
model | Specifies the model used for evaluation. | Any available provider model (e.g., gpt-3.5-turbo, gpt-4) |
additional_columns | A dictionary of additional columns present in your dataset to include in the evaluation prompt. Use it to map the column name to the placeholder name you reference in the criteria. For example: ({"mycol": "question"}. | Custom dictionary (optional) |
BinaryClassificationPromptTemplate
| Parameter | Description | Options |
|---|---|---|
criteria | Free-form text defining evaluation criteria. | Custom string (required) |
target_category | Name of the target category you want to detect (e.g., you care about its precision/recall more than the other). The choice of “target” category has no impact on the evaluation itself. However, it can be useful for later quality evaluations of your LLM judge. | Custom category (required) |
non_target_category | Name of the non-target category. | Custom category (required) |
uncertainty | Category to return when the provided information is not sufficient to make a clear determination. | unknown (Default), target, non_target |
include_reasoning | Specifies whether to include the LLM-generated explanation of the result. | True (Default), False |
pre_messages | List of system messages that set context or instructions before the evaluation task. Use it to explain the evaluator role (“you are an expert..”) or context (“your goal is to grade the work of an intern..”). | Custom string (optional) |
MulticlassClassificationPromptTemplate
| Parameter | Description | Options |
|---|---|---|
criteria | Free-form text defining evaluation criteria. | Custom string (required) |
target_category | Name of the target category you want to detect (e.g., you care about its precision/recall more than the other). The choice of “target” category has no impact on the evaluation itself. However, it can be useful for later quality evaluations of your LLM judge. | Custom category (required) |
category_criteria | A dictionary with categories and definitions. | Custom category list (required) |
uncertainty | Category to return when the provided information is not sufficient to make a clear determination. | unknown (Default) |
include_reasoning | Specifies whether to include the LLM-generated explanation of the result. | True (Default), False |
pre_messages | List of system messages that set context or instructions before the evaluation task. | Custom string (optional) |
OpenAIPrompting descriptor
OpenAIPrompting descriptor
OpenAIPrompting
There is an earlier implementation of this approach withOpenAIPrompting descriptor. See the documentation below.OpenAIPrompting DescriptorTo import the Descriptor:response and get a summary Report:Descriptor parameters
-
- The text of the evaluation prompt that will be sent to the LLM.
- Include at least one placeholder string.
-
- A placeholder string within the prompt that will be replaced by the evaluated text.
- The default string name is “REPLACE”.
-
- The type of Descriptor the prompt will return.
- Available types:
num(numerical) orcat(categorical). - This affects the statistics and default visualizations.
-
- An optional placeholder string within the prompt that will be replaced by the additional context.
- The default string name is “CONTEXT”.
-
- Additional context that will be added to the evaluation prompt, which does not change between evaluations.
- Examples: a reference document, a set of positive and negative examples, etc.
- Pass this context as a string.
- You cannot use
contextandcontext_columnsimultaneously.
-
- Additional context that will be added to the evaluation prompt, which is specific to each row.
- Examples: a chunk of text retrieved from reference documents for a specific query.
- Point to the column that contains the context.
- You cannot use
contextandcontext_columnsimultaneously.
-
- The name of the OpenAI model to be used for the LLM prompting, e.g.,
gpt-3.5-turbo-instruct.
- The name of the OpenAI model to be used for the LLM prompting, e.g.,
-
- A dictionary with additional parameters for the OpenAI API call.
- Examples: temperature, max tokens, etc.
- Use parameters that OpenAI API accepts for a specific model.
-
- A list of possible values that the LLM can return.
- This helps validate the output from the LLM and ensure it matches the expected categories.
- If the validation does not pass, you will get
Noneas a response label.
-
- A display name visible in Reports and as a column name in tabular export.
- Use it to name your Descriptor.