- Evidently Python library helps run data and AI evaluations with 100+ metrics, a declarative testing API, and a lightweight visual interface to explore the results. You can also use it to generate synthetic data and run prompt optimization workflows.
- Evidently platform provides AI testing and observability infrastructure for production systems. It includes tracing, storage for AI application data and evaluation runs, test dataset management, and dashboards to visualize evaluation results.
Get started
Run your first evaluation in a couple of minutes.LLM evaluation
Evaluate the quality of LLM system outputs.
ML monitoring
Test tabular data quality and data drift.
Feature overview
What you can do with Evidently.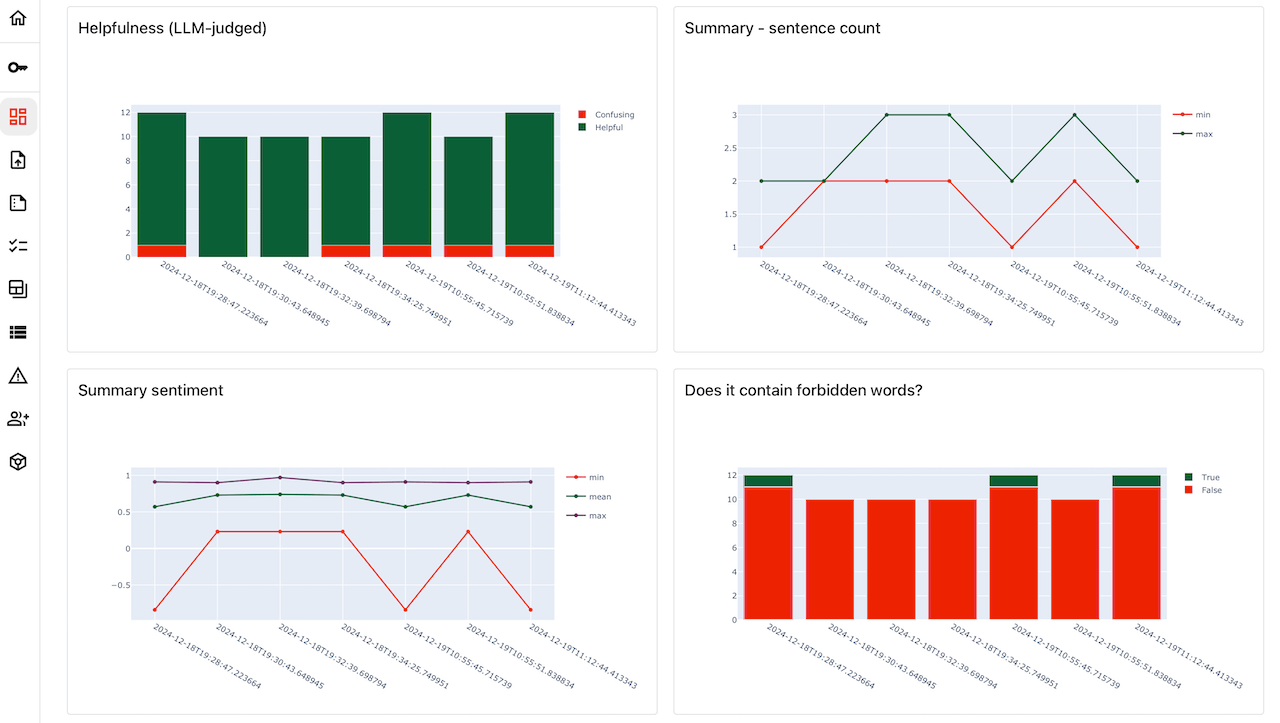
Evidently Platform
Key features of the AI observability platform.
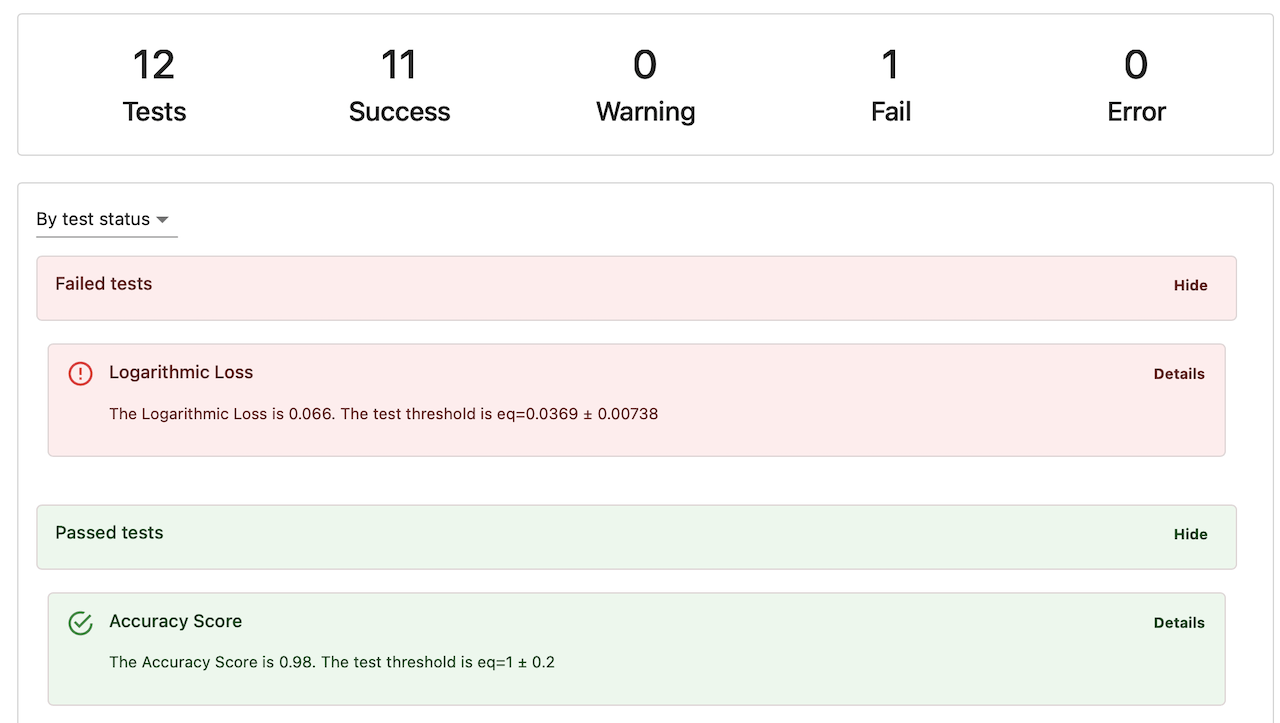
Evidently library
How the Python evaluation library works.
Learn more
Metrics
Browse the catalogue of 100+ evaluations.
Cookbook
End-to-end code tutorials and examples.