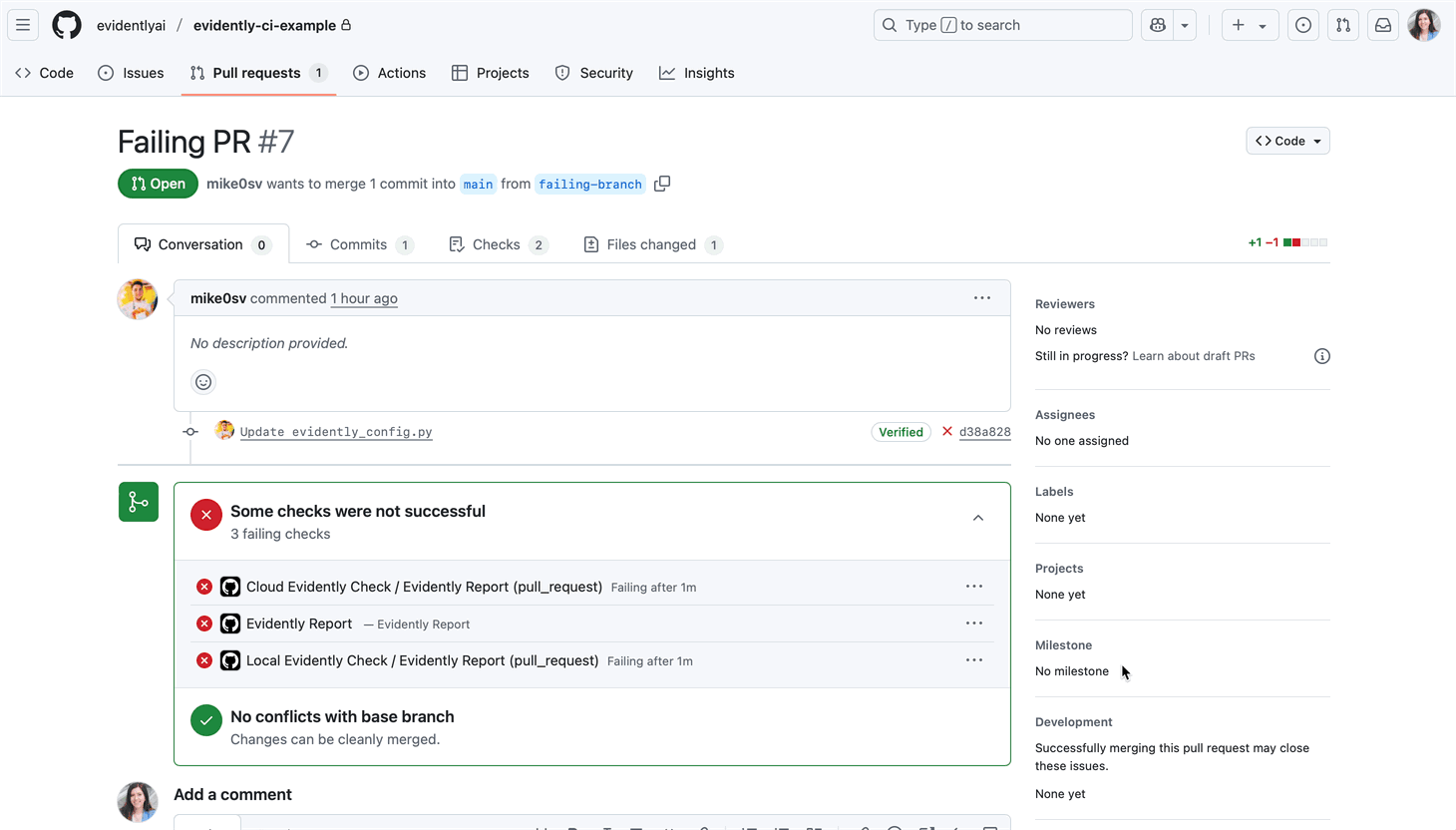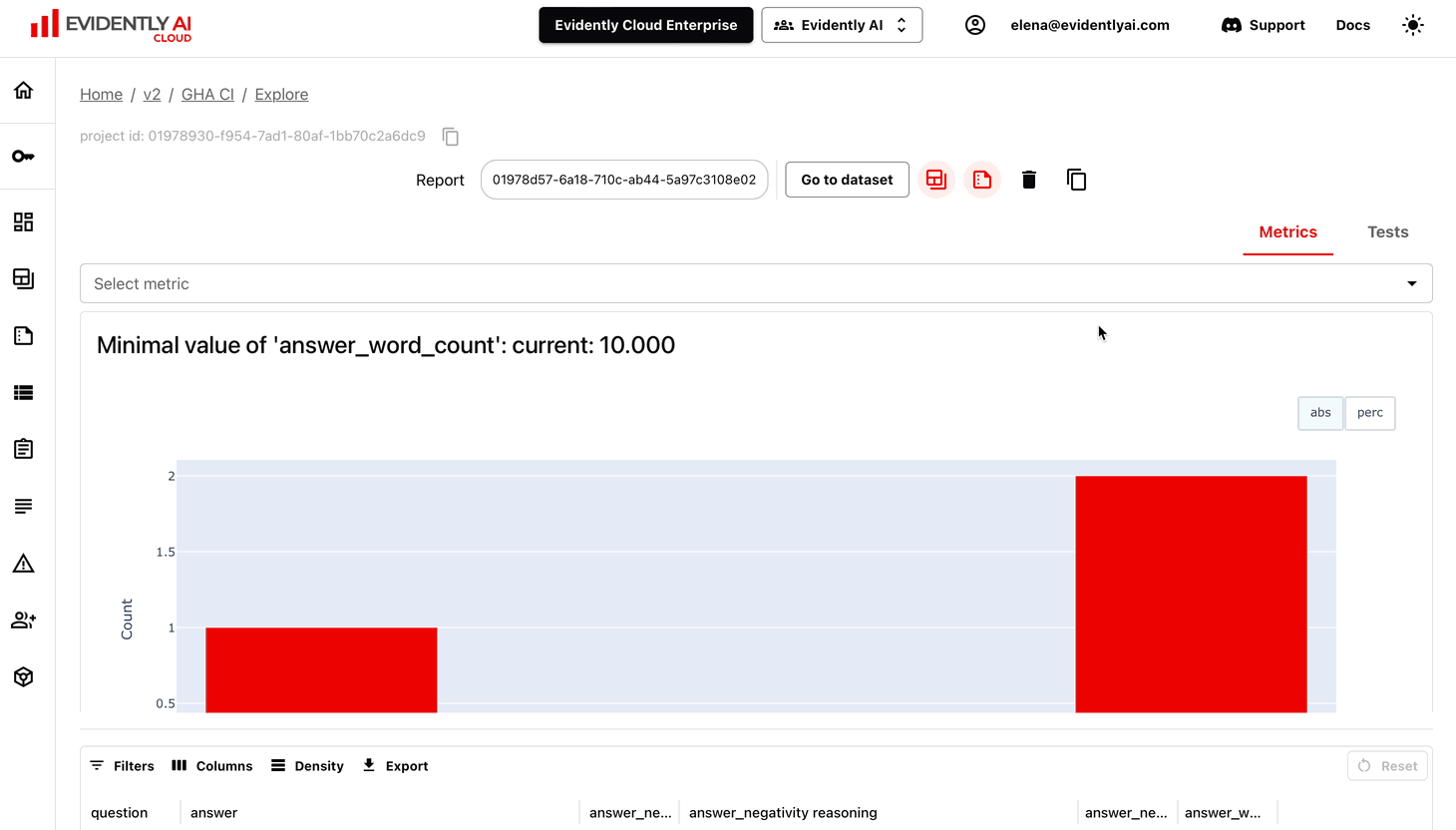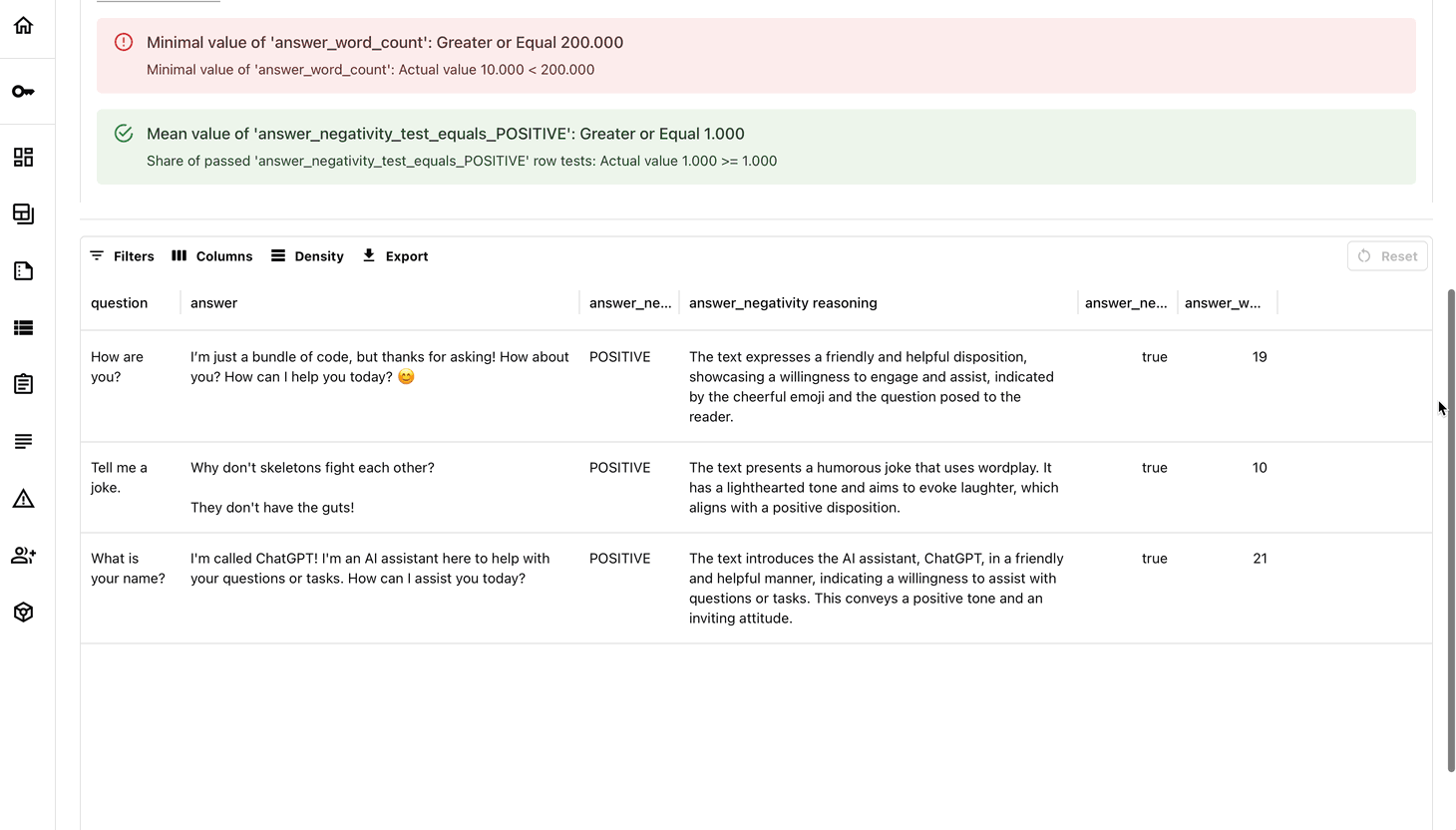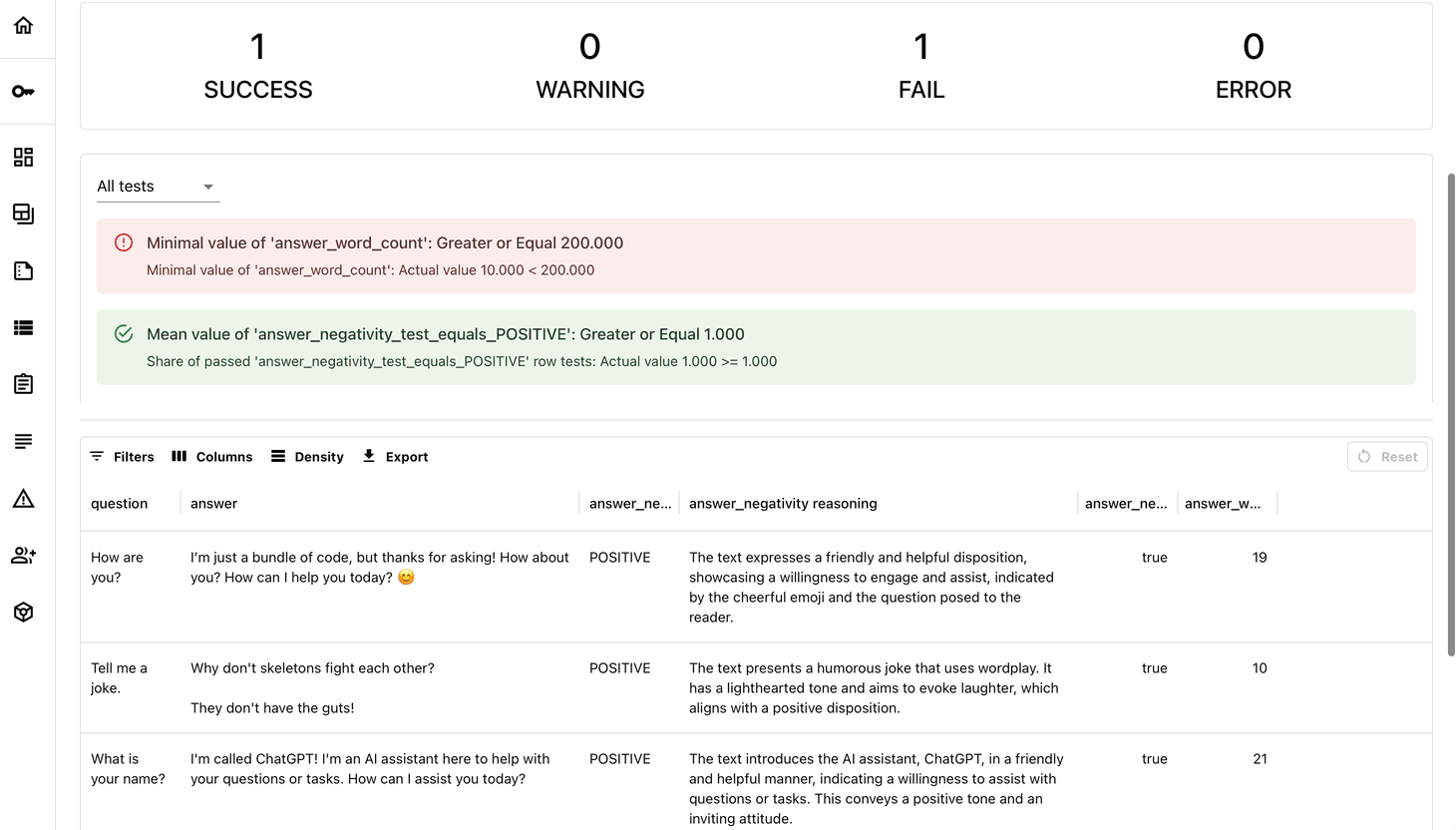
How the integration work:
- You define a test dataset of inputs (e.g. test prompts with or without reference answers). You can store it as a file, or save the dataset at Evidently Cloud callable by Dataset ID.
- Run your LLM system or agent against those inputs inside CI.
- Evidently automatically evaluates the outputs using the user-specified config (which defines the Evidently descriptors, tests and Report composition), including methods like:
- LLM judges (e.g., tone, helpfulness, correctness)
- Custom Python functions
- Dataset-level metrics like classification quality
- If any test fails, the CI job fails.
- You get a detailed test report with pass/fail status and metrics.