- Just the inputs, or
- Both inputs and expected outputs (ground truth).
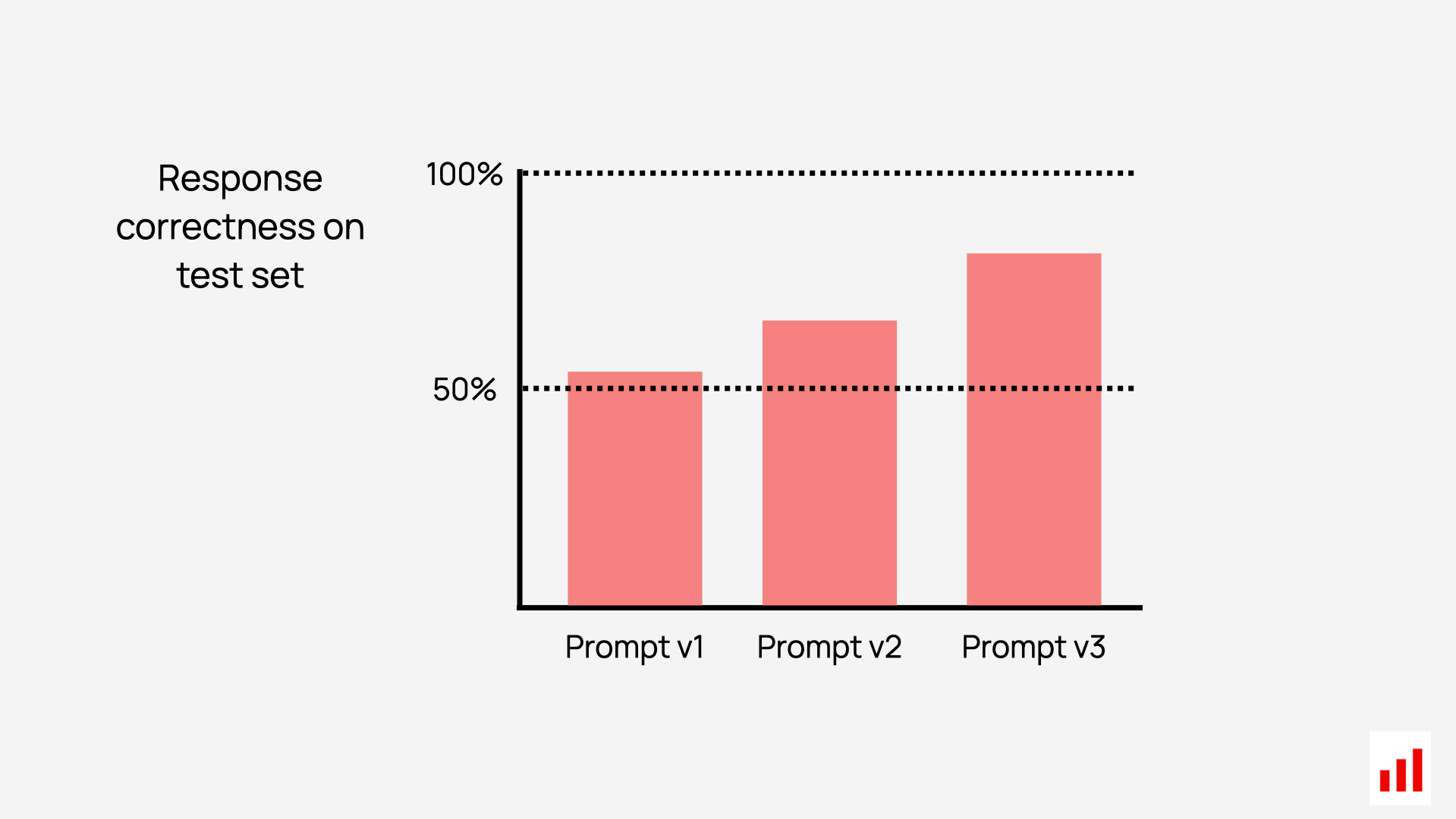
- Run experiments and track if changes improve or degrade system performance.
- Run regression testing to ensure updates don’t break what was already working.
- Stress-test your system with complex or adversarial inputs to check its resilience.
- You’re starting from scratch and don’t have real data.
- You need to scale a manually designed dataset with more variation.
- You want to test edge cases, adversarial inputs, or system robustness.
- You’re evaluating complex AI systems like RAG and AI agents.

- Quickly generate hundreds structured test cases.
- Fill gaps by adding missing scenarios and tricky inputs.
- Create controlled variations to evaluate specific weaknesses.